1、创建正则表达式的两种方法
1.1 字面量形式
|
|
1.2构造函数形式
|
|
2、元字符
2.1 元字符及其含义
| 字符 | 含义 |
|---|---|
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \n | 换行符 |
| \r | 回车符 |
| \0 | 空字符 |
| \f | 换页符 |
| \cX | 与X对应的控制字符(Ctrl + X),例如:\cZ代表 Ctrl+Z |
3、字符类
3.1 构件字符类:使用[]构件字符类
|
|
3.2 字符类取反:使用元字符^构件反向类
|
|
3.3 构件范围类:使用[]和’-‘可以构建范围类
- [a-z]表示包括26个小写字母的闭区间
- [a-zA-Z] 表示大小写字母的闭区间
- [0-9] 表示所有数字
|
|
4、js预定义类及边界
4.1 预定义类及其含义
预定义类是范围类的缩写
| 字符 | 等价类 | 含义 |
|---|---|---|
. |
[^\r\n] |
除了回车和换行符之外的所有字符 |
\d |
[0-9] |
数字字符 |
\D |
[^0-9] |
非数字字符 |
\s |
[\t\n\x0B\f\r] |
空白符 |
\S |
[^\t\n\x0B\f\r] |
非空白符 |
\w |
[a-zA-Z_0-9] |
单词字符(字母、数字、下划线) |
\W |
[^a-zA-Z_0-9] |
非单词字符 |
4.2 边界匹配字符及其含义
| 字符 | 含义 |
|---|---|
^ |
以xxx开始 |
$ |
以xxx结束 |
\b |
单词边界 |
\B |
非单词边界 |
举个栗子:
|
|
4.3 范围匹配字符及其含义
| 字符 | 含义 |
|---|---|
g |
全局匹配 |
i |
忽略大小写 |
m |
多行匹配 |
4.4 量词匹配字符及其含义
| 字符 | 含义 |
|---|---|
? |
出现0次或1次(最多出现1次) |
+ |
出现1次货多次(至少出现1次) |
* |
出现0次或多次(任意次) |
{n} |
出现n次) |
{n,m} |
出现n次到m次 |
{n,} |
至少出现n次 |
举一堆例子:
出现最多1次
出现至少一次
出现任意次
出现10次
出现2-10次
出现至少100次
出现最多10次
6、贪婪与非贪婪模式的区别
6.1 贪婪模式
按“尽可能多”进行匹配,具体看下方例子
|
|
6.2 非贪婪模式
按“尽可能少”进行匹配,一旦匹配成功,不再进行匹配。要启用非贪婪模式,只需要在量词后面加上?即可。
|
|
7、分组匹配
7.1 不分组
默认情况下,{n} 表示紧挨着它的字符重复n次
|
|
7.2 分组
使用小括号()可以对表达式进行分组,分组后$1、$2...$n分别代表从左到右的分组。
|
|
7.3 或逻辑
使用|表示或逻辑
举一堆例子:


7.3 反向引用
使用小括号()对表达式进行分组后,可以用$1、$2...$n来引用对应分组的匹配值,从而实现反向引用(即对匹配值进行各种操作)
|
|
分组示意图
7.4 忽略分组
在每个分组的前面加上问号冒号?:可忽略当前分组。如下图所示,中间的分组已经被忽略。此时$1表示第一个分组,$2表示第3个分组
8、前瞻
- 正则表达式从左向右解析,文本尾部的方向称为‘前’,前瞻就是在正则表达式匹配到规则的时候,向前检查是否符合断言。
- 后顾/后瞻则方向相反。JavaScript不支持后顾!!
- 符合特定断言称为
肯定/正向匹配,不符合特定断言否定/负向匹配
| 名称 | 正则 | 备注 |
|---|---|---|
| 正向前瞻 | exp(?=assert) |
|
| 负向前瞻 | exp(?!=assert) |
|
| 正向后顾 | exp(?<=assert) |
JavaScript不支持 |
| 负向后顾 | exp(?<!assert) |
JavaScript不支持 |
举一堆例子:
1、匹配单词后面是数字的的内容,并替换成X(括号内的正则不作为替换的对象)
|
|
2、匹配单词后面不是数字的的内容,并替换成Q(括号内的正则不作为替换的对象)
|
|
9、RegExp对象属性及方法
9.1 对象属性
- global:是否全文搜索,默认false
- ignoreCase:是否大小写敏感,默认false
- multiline:多行搜索,默认false
- lastIndex:当前表达式匹配内容的最后一个字符的下一个位置
- source:正则表达式的文本字符串(正则表达式的原本内容)
举个例子:
9.2 RegExp.prototype.test(str)方法
test()方法用于测试字符串参数中,是否存在匹配正则表达式模式的字符串,存在返回true,否则返回false。
非全局匹配,没有lastIndex属性,仅判断是否存在匹配项,不返回相关内容,匹配速度最快。

全局匹配,存在lastIndex属性,会从上次匹配的地方继续匹配,每次匹配lastIndex会改变,所以会出现返回
false的情况(如下图所示)
9.3 RegExp.prototype.exec(reg)方法
exec()方法使用正则表达式模式对字符串执行搜索,并更新全局RegExp对象的属性以反映匹配结果。
- 全局匹配
如果没有匹配的文本返回null,否则返回一个结果数组,数组的index和input,分别是匹配字符串第一个字符的索引和原始匹配对象。
结果数组第一个元素是与正则表达式相匹配的第一个文本,第二个元素是匹配到的分组内容。
举栗子:

举栗子:

- 非全局匹配(lastIndex始终为0)
如果没有匹配的文本返回null,否则返回一个结果数组。
结果数组第一个元素是与正则表达式相匹配的文本
第二个元素是与RegExpObject的第一个子表达式相匹配的文本(如果有的话)
第三个元素是与RegExp对象的第二个子表达式相匹配的文本(如果有的话),以此类推
举栗子: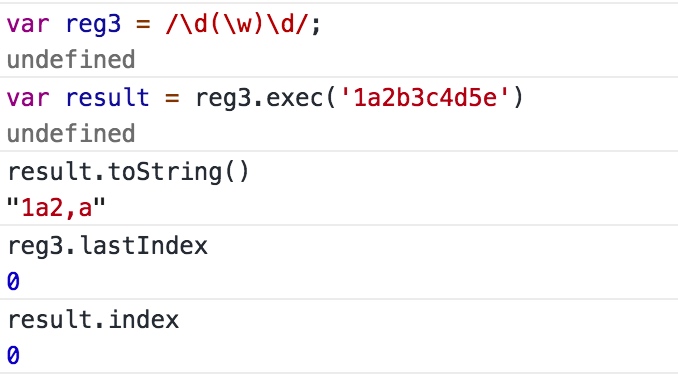
9、字符串对象方法
9.1 String.prototype.search(reg)方法
search()方法用于检索字符串中指定的子字符串,或检测与正则表达式相匹配的子字符串- 该方法返回第一个匹配结果的index值,找不到则返回 -1
search()方法不执行全局匹配,它会忽略g标志,并且总是从字符擦混的开始进行检索search()方法会将传入的参数,尝试转化成正则再进行匹配

9.2 String.prototype.match(reg)方法
- match()方法将检索字符串,以找到一个或多个与regexp匹配的文本
- regexp是否具有g标识,对结果影响很大!!
非全局调用(没有g标识,忽略lastIndex属性)
- 如果regexp没有g标识,那么match()方法就只能在字符串中执行一次匹配
- 如果没有找到任何匹配的文本,将返回null
如果找到匹配的文本,将返回一个数组,其中存放了与它找到的匹配文本有关的信息:
返回数组的第一个元素存放的是匹配文本,其余的元素存放的是与正则表达式的子表达式匹配的文本。
除了常规的数组元素外,返回的数组还包含了2个对象属性:- index声明匹配文本的起始字符在字符串的位置
- input声明对stringObject的引用
举例子:

全局调用
如果regexp具有g标识,match()方法将执行全局检索,找到字符串中的所有匹配子字符串
- 如果没有任何匹配的子字符串,则返回null
- 如果找到一个或多个匹配字符子串,则返回一个数组
- 数组元素中存放的是字符串中所有的匹配子串,而且也没有index属性或input属性
举例子:

9.3 String.prototype.split(reg)方法
该方法会将参数尝试转化成正则表达式,再进行匹配
|
|
9.4 String.prototype.replace()方法
该方法支持三种不同的传参方式(用法),同样会尝试转化成正则表达式,再进行匹配
- 第一种用法
String.prototype.replace(str, replaceStr)
|
|
- 第二种用法
String.prototype.replace(reg, replaceStr)
|
|
- 第三种用法
String.prototype.replace(reg, function)
每次匹配成功,都会回调function函数,function的参数如下:
1、匹配字符串
2、正则表达式分组内容,没有分组则没有该参数
3、匹配项在字符串中的index
4、原字符串
举例子:
|
|
执行效果: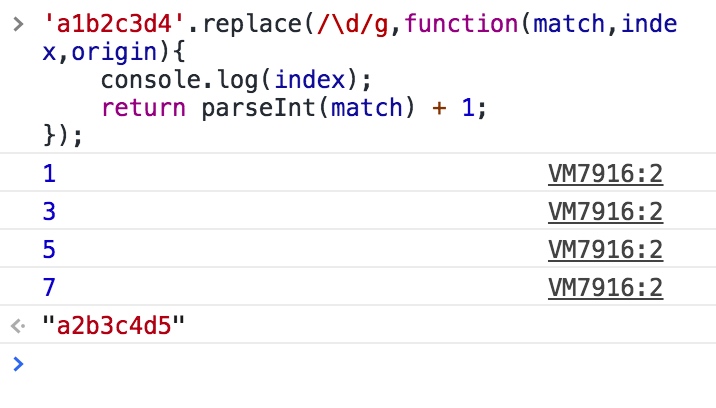
再举一个例子:
|
|
执行效果: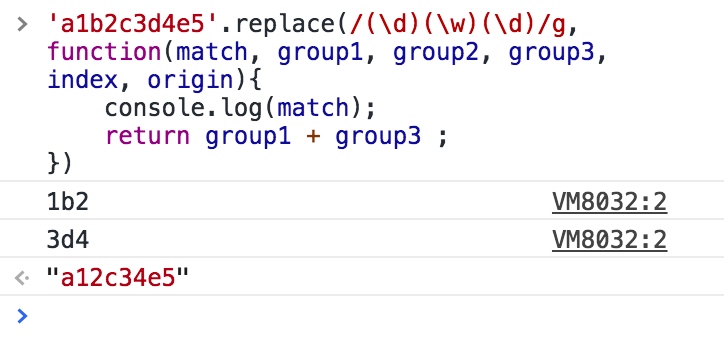
声明:以上内容,不一定全部正确,仅供参考!